Problem
I have been working on an application sending out millions of HTTP Post requests. The application has an issue, it has a high memory usage. It is using 2 GB over the expected of a few hundred megabytes.
An investigation revealed that a percentage of (random) requests are failing because of invalid request content. When a request fails, the application has a built in resiliency policy to wait with an exponential backoff and retry the failed requests. Unfortunately, that failed request is determined to fail again, hence triggering the above policy 3 times, before giving up for all.
One could figure, that the retry policy is referencing the failing requests for considerably longer period in memory. Let’s not trust our gusts but do some measurements instead.
Mid-life crisis is when an application does not behave according to the generational hypothesis (young objects die fast, old objects live even longer), young objects outlive Gen0, but as they reach Gen1 or Gen2 die there quickly.
Repro
To examine this behavior from a closer look, I created a sample service and client application. The service exposes a POST endpoint, and regardless of the response, it is using a random number generator to fail about 30% of the requests (this is a larger fail rate compared to the original use case, but required to compensate the smaller number of total requests). The client application sends out 1000 requests in a loop, each has a 2 ms delay after the previous request. Then the application awaits all the responses. Each request sends out an array of 65536 bytes that is large enough to have an impact, but small enough to be allocated on the small object heap.
I repeated the tests with the following different configurations:
- resiliency policy
- no retries
- retry 3 times
- wait and retry 3 times
- requests’ memory
Here are the Polly policies used within the tests:
registry.Add(WaitAndRetry3, Policy.HandleResult<HttpResponseMessage>(x => !x.IsSuccessStatusCode)
.WaitAndRetryAsync(3, counter => TimeSpan.FromSeconds(2 << counter)));
registry.Add(Retry3, Policy.HandleResult<HttpResponseMessage>(x => !x.IsSuccessStatusCode)
.RetryAsync(3));
registry.Add(NoOp, Policy.NoOpAsync<HttpResponseMessage>());
The output of the client app with no retry policy (failing about 30% of the requests):
Succeeded 698, 69.8%
The output of the client app with 3 retries (about 0.3^4*100=0.8% would fail):
Succeeded 994, 99.4%
Analysis
To measure the allocated memory and the application behavior, I used PerfView to sample allocations and garbage collection events.
The client application calls GC.Collect() before exiting, as the only induced GC. In the next sections I am showing and explaining the differences between the proposed configurations based on the PerfView sessions.
Not Pooled byte arrays – No Retries (Baseline)
private async Task<int> SendRequest(HttpClient client)
{
byte[] data = new byte[65536];
try
{
var response = await client.SendAsync(new HttpRequestMessage(HttpMethod.Post, _url) { Content = new ByteArrayContent(data) }, HttpCompletionOption.ResponseContentRead);
return response.IsSuccessStatusCode ? 1 : 0;
}
catch (Exception)
{
return 0;
}
}
In this use case the application allocates a new byte array for each request, and uses a NoOp retry policy, meaning that Polly will not retry, nor provide any resiliency to the requests.
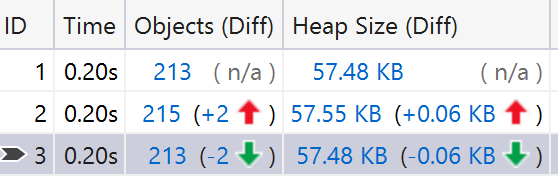
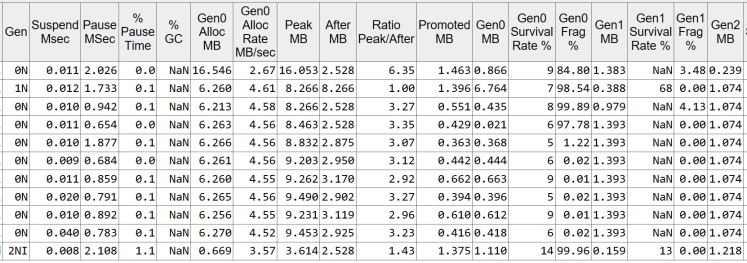
In this configuration the application allocates totally 73.529 MB and the max heap size is 16.053 MB, meaning most of the allocated memory ends up as garbage.
The GC runs 11 times, out of which the only Gen2 collection is the induced one, before application shuts down.
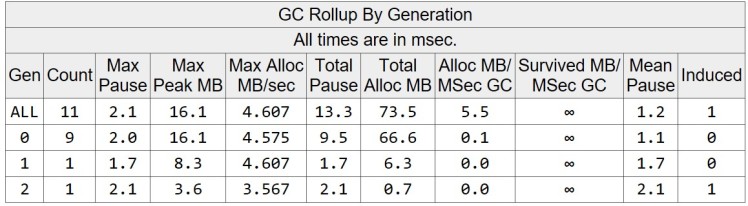
If we take a look at the individual GC events, we can observer that the size of Gen1 (Gen1 MB column) and Gen2 (Gen2 MB column) is relatively small when the GC finished. This is because most of the objects are allocated in Gen0 and most of them die very young. The Gen0’s survival rate is only a single digit, meaning most of the allocated memory is already garbage when the GC runs.
This behavior corresponds to the weak generational hypothesis.
Not Pooled byte arrays – Retry 3 times
In this configuration the application allocates a new byte array for each request and uses a retry policy with the requests. It means if the request fails it tries to send the request again immediately, up until it has retried it 3 times.
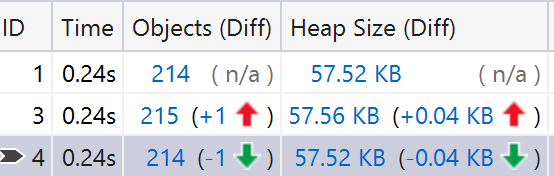
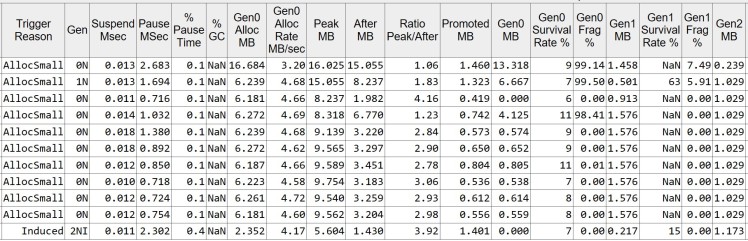
The total allocated memory is 75.090 MB while the max heap size is 16.025 MB. We have the same type and same number of GC events. Looking at the detailed events below, we can spot that the size of the heap (After MB) is slightly larger, as well as the Gen0 survival rate. I would not call this different significant at all, allocated objects are still short lived, and they die soon. A couple of requests that are retried might outlive the Gen0 collection.
Not Pooled byte arrays – Wait and Retry 3 times
In this use case the application allocates a new byte array for each request, and uses a wait and retry policy with the requests. It means if the request fails, it waits a certain amount of time before it tries to send the request again.
The amount of wait time is determined by an exponential backoff policy, where the counter means the number of retries on the individual requests:
TimeSpan.FromSeconds(2 << counter)
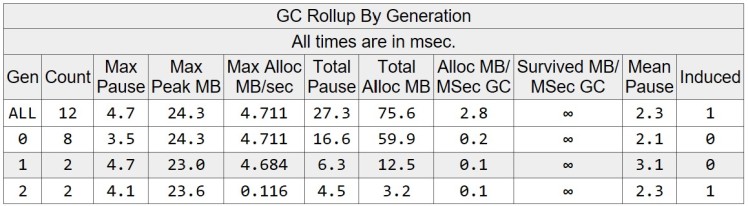
The total allocated memory is 75.623 MB while the max heap size is 24.309 MB. A careful reader can already spot that the total amount of allocated memory is about the same, while the max heap size increased significantly. If we observe the GC events, we can see that there is one additional Gen1 and Gen2 collection. That means that there are more objects getting promoted to higher generations.
Looking at the details, we can spot the increased size of Gen1 and Gen2.
This use case fits less well to the weak or strong generational hypothesis. Objects are still relatively short lived, though live long enough to be promoted into Gen1 and Gen2. This is caused by the exponential backoff policy. The heap size also grows throughout the lifetime of the application, except for final induced GC (when all requests have completed). After this full GC, most objects promoted to Gen1 and Gen2 become garbage and the size of the heap drops significantly. This indicates that most of these objects were experiencing a mid-life crisis.
Note, that exponential backoff policy is a good behavior, we shall not replace it with simple retries to avoid mid-life crisis. Though it is important to know what consequences it might have on the application’s memory usage, as described above. One way to address this problem would be combining the WaitAndRetry with a CircuitBreaker policy.
Pooled byte arrays – No Retries
One might raise a question, what if we had pooled and reused the byte arrays for the requests. Instead of allocating a new array for each request, we can ask for a given size of memory from ArrayPool.Shared instance, and return the rented array once the request completes.
private async Task<int> SendRequest(HttpClient client)
{
byte[] data = ArrayPool<byte>.Shared.Rent(65536);
try
{
var response = await client.SendAsync(new HttpRequestMessage(HttpMethod.Post, _url) { Content = new ByteArrayContent(data) }, HttpCompletionOption.ResponseContentRead);
return response.IsSuccessStatusCode ? 1 : 0;
}
catch (Exception)
{
return 0;
}
finally
{
ArrayPool<byte>.Shared.Return(data);
}
}
In this use case the application uses an array pool to get a chunk of memory, (it could fill the requested memory with data) and send it to the server. Once a response is returned, the memory is returned to the pool. There is no resiliency enabled, if the request fails it will not be retried.
The total allocated memory is 8.751 MB and the max heap size measured is 8.762 MB. The GC is triggered only once by the application, which is the induced GC.
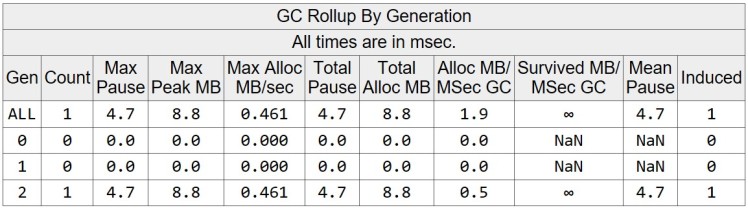
The individual GC events table shows slightly more information about the heap. In this case a lot less memory is allocated compared to the non-pooled, non-resilient use case. This is because we can reuse existing arrays from the pool, in case any given two requests are not overlapping.

Pooled byte arrays – Retry 3 times
In this use case the application uses the same ArrayPool technique to rent a data array for the request, but it has a retry resiliency enabled, which will make the application retry failing requests. There is no wait time or backoff policy configured between the retries.
The total allocated memory is 10.435 MB and the max heap size is 10.385 MB. There is a single induced GC event before the application exits.
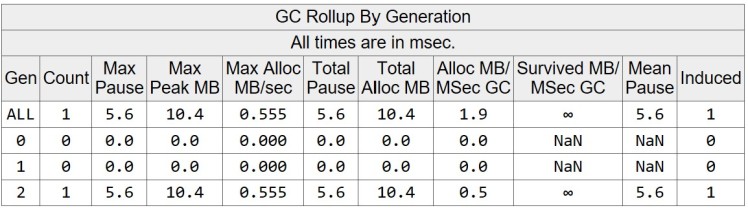
In this use case we notice a similar behavior and comparison to the non-pool tests. The application uses slightly more memory, which is because some of the HTTP requests needs to be retried, hence these requests keep on to data rented data array for a longer time. It means more requests will end up running overlapped, so more byte arrays will be required from ArrayPool will result it allocating more pooled objects.

Pooled byte arrays – Wait and Retry 3 times
In this use case the application uses an ArrayPool to pool the byte arrays for the request, and it also waits with an exponential backoff policy if a request fails, before the retry.
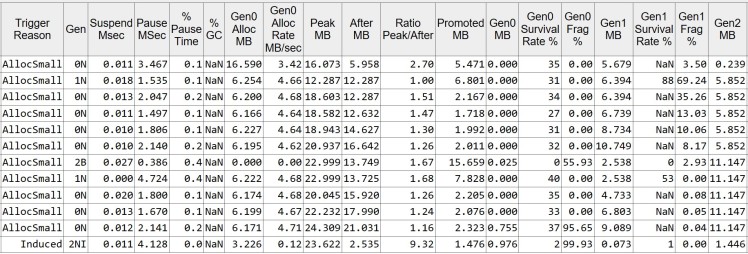
The total allocated memory is 19.878 MB and the max heap size is 19.510 MB. If we look at the GC events, there is a one triggered by AllocSmall and one induced before application exits.
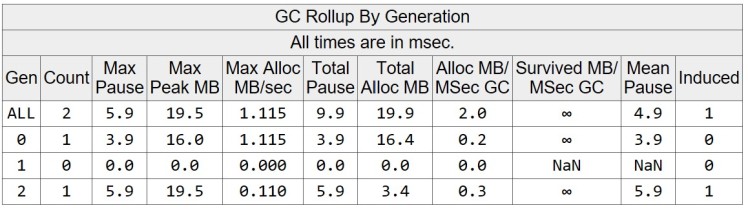
Looking at the individual events we may notice that most of the memory is promoted to higher generation and eventually to Gen2.

Final thought, the implementation of ArrayPool: TlsOverPerCoreLockedStacksArrayPool does have a trimming logic that may free up some of the unused pooled objects on a full garbage collection.
Summary
The tests above show examples on how a retry policy and memory management technique may have an effect on the application’s memory footprint. I find it useful to be aware of such behavior patterns, but nobody should deduce broad conclusions based on these. Every application is different, requests can be differently sized, numbered, their duration vary, that all may result significantly different generation sizes. As a general rule, always measure the application first.